[缘由]: 本文是 google 在今年NSDI上一篇会议论文,介绍他们运行了8年的负责全球业务的负载均衡服务 Maglev。从文中可以看到 Maglev 中使用的技术,例如 ECMP、BGP、GRE、Kernel Bypass、一致性哈希等都是常见且成熟的技术方案,但他们的组合方案以及后面的监控/调试手段都让我收益良多。因此就在周末的时候翻译了一下,和大家共享。经验较少、水平有限,翻译失当地方欢迎批评指正。原文:[http://research.google.com/pubs/archive/44824.pdf]
摘要
Maglev 是 Google 的网络负载均衡器。
他是运行在通用 Linux 服务器上的大型分布式软件系统。
不像传统的硬件软件负载均衡器,
maglev 无需专门的部署物理机架,
同时他的能力能够简单地通过增减机器来调节。
网络路由器通过等价多路径路由(ECMP) 均等地分发给 maglev 机器;
每台 Maglev 机器再匹配数据包与他们对应的服务,
然后把包平均分发给每个服务Endpoint。
为了适应比较高或者不断增长的流量,Maglev 专门优化包转发性能。
单台 Maglev 机器能够满足万兆的小包流量。
为了最小化意外错误或者故障给面向连接协议的服务造成影响,
Maglev 同时具备一致性哈希和连接追踪功能。
Maglev 从 2008 年开始就在Google 内部服务,它支撑全球快速增长的 Google 服务,同时为 Google Cloud Platform 提供网络负载均衡服务。
1. 介绍
Google 是全球互联网流量的主要源头[29, 30]。
它提供了数以百计的面向用户的服务,同时还有不断增长的许许多多托管在 Cloud Platform[6] 的服务。
著名的 Google 服务,比如 Google 搜索、Gmail 每秒能够收到来自全球各地的百万计的请求, 极大的依赖底层服务基础架构。
为了满足如此高压力且低延迟,
Google 的服务需要在全球范围多个集群部署一堆服务器。
每个集群中,为了有效地使用资源和防止个别服务器过载,
一个基本的功能就需要均衡所有服务器的流量。
从而使网络负载均衡器成为 Google 生产环境的网络基础设施中的重要组成部分。
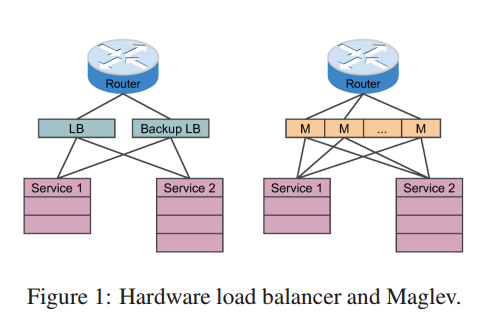
一个网络负载均衡器通常由多台分布在路由器和服务端(通常是TCP/UDP服务器)之间的设备组成,
例如图一所示。
它负责每个包的匹配和转发。
网络负载均衡器传统由硬件设备实现[1,2,3,5,9,12,13],一般来说有诸多限制。
首先,他们的可扩展性通常受限于点单的最大能力,导致无法满足 Google 的增长。
其次,他们的高可用不可满足 Google的需求。
尽管他们经常成对地部署以避免单点故障,但是只能提供 1 + 1 冗余。
第三,他们缺少快速迭代所需要的灵活性和可编程性,修改一台硬件负载均衡设备并非不可能,
只是通常比较难。
第四,升级代价大。升级一台硬件负载均衡通常包含购买新设备以及物理部署。
因为以上种种限制,我们研究和寻求另一种解决方案。
所有的服务所在集群都是常规服务器,我们可以在这些服务器上
以分布式软件的形式构建网络负载均衡器。
一个软件负载均衡系统有很多优点。
我们可以应用 scale-out 模型来应对可扩展性。
LB 的容量可以通过增加系统中机器的数量来改善: 通过ECMP 转发,
流量可以均衡地经过所有机器。
可用性可可靠性可以通过系统提供 N+1 冗余保证。
对系统的整体把控,我们可以快速地添加、测试和部署新特性。
同时,也极大的简化 LB 服务的部署: 服务只使用集群中现有的机器。
我们也可以将统一集群中服务切分成多个分片(shards) 以达到性能的隔离。
尽管有如上诸多优点,设计和实现一个软件网络负载均衡器非常复杂和富有挑战性。
首先,系统中的每个独立机器必须提供高吞吐量。
设 N 为系统中机器的数量, T 为单台机器的最高吞吐量。
整个系统的最高容量限制在 N * T。
如果 T 不够高,提供满足所有服务的容量并不划算[22]。
这个系统作为一个整体必须提供连接持久化(connection persistence):
属于同一连接的数据包必须始终分发到同一个服务上。
这个确保了服务质量因为集群经常变化和故障非常常见[23, 40]。
这篇论文提供了 Maglev,一个快速且可靠的软件负载均衡系统。
从 2008 年开始,Maglev 成为 Google 前端服务基础架构中重要组成部分。
如今几乎承担 Google 所有来自用户的流量。
为了利用当前高速服务器网络技术[18, 41, 35, 31], 每台 Maglev 机器都能线速地处理每个小包。
通过一致性哈希(consistent hashing)和连接追踪(connection tracking), Maglev 提供了在频繁变更和未知故障下的可靠包分发。
尽管本文描述一些技术已经存在许多年,本文展示如果利用这些技术构建一个系统(operational system)。
本文的主要贡献?为:
1)展现 Maglev 的设计和实现,
2)分享全球范围内操作 Maglev 的经验以及
3)通过多重评估证明 Maglev 的能力。
2. 系统概况
本节概要地介绍了 Maglev 作为一个网络负载均衡器如何工作。
我们先简单地介绍下 Google 的前端服务架构,接下来介绍 Maglev 系统服务配置。
2.1 前端服务架构
Maglev 部署在 Google 前端服务位置,包含多种集群规格。
为了化繁为简,本文中,我们只关注于构建一个小型的集群,然后简要地描述大型集群的构建。
图2 显示一个小型集群的 Google 前端服务架构的概况。
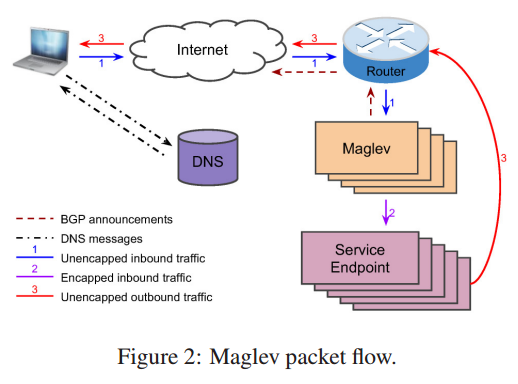
每个 Google 服务都有一个或者多个 VIP。
一个 VIP 和物理 IP 的区别在于 VIP 没有绑给某个特定的网卡,
但是为 Maglev 背后多个服务Endpoint提供服务。
Maglev 关联每个 VIP 到具体的服务,然后通过 BGP 宣告给上游路由器;
然后路由再把 VIP 宣告给 Google 的骨干网。
这些 VIP 宣告给互联网使得他们能够在全球内被访问。
Maglev 同时处理 IPv4 和 IPv6 流量,以下所有的描述均可用于这两者。
当用户访问www.google.com 上的 Google 服务,首先浏览器先发送一个 DNS 请求,
然后从某个 Google 的权威DNS服务器上获取 DNS 的响应(可能直接从本地缓存中或者本地DNS的缓存)。
DNS 服务考量服务与用户距离以及负载情况,返回服务的 VIP[16]。
然后浏览器尝试与该 VIP 建立连接。
当路由器接收到一个 VIP 数据包,通过 ECMP 将数据包路由到 Maglev 集群中的某台机器上,
因为所有 Maglev 集群都用相当的代价宣告同一个 VIP。
当 Maglev 的机器接收到数据包, 它从一堆关联到该 VIP 的服务Endpoint中选个一个,
然后用 GRE 封包,外层的 IP 即对端的IP。
当数据包到达所选的服务 endpoint 使进行解包和消费。响应时源地址用VIP 填充,目的地址为用户 IP。
我们使用直接服务返回(Direct Server Return, DSR) ,将响应直接发送给路由器,
这样 Maglev 无需处理通常是大包的响应包。
本文关注来自用户的进向的流量的负载均衡。
DSR的实现则在本文的范畴之外。[注: DSR实现需要依赖每个服务上的一个模块,
用于GRE拆包和响应包的组装]。
2.2 Maglev 配置
如前一节的描述, Maglev 负责像向路由器宣告 VIP 和转发 VIP 流量到服务 endpoint 。
每台 Maglev 包含一个控制器和转发器,如图3 所示。
控制器和转发器都需要从配置对象中学习 VIP。
配置对象则从配置文件中读取或者通过 RPC 接收来自外部系统控制。
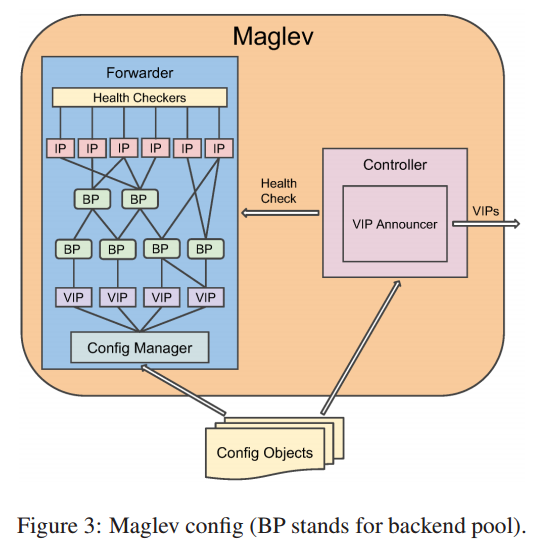
每台 Maglev 机器,控制器周期性地转发器的健康状态。
根据检查结果, 控制器决定通过 BGP 宣告或者撤回 VIP。
这个确保路由器只路由包到健康的 Maglev 机器。
Maglev 接收的所有 VIP 数据包都是由转发器处理。
在转发器中, 每个 VIP 配置有 1 个或者多个后端池。
除非另外的说明,这些后端就是服务 endpoint 。
一个后端池可能包含服务 endpoint 的物理地址,
可能包含其他后端池(如此则通用的后端池则无需重复配置)。
每个后端池,根据需求关联了一个或者多个对后端服务的健康检查方法。
相同服务可能在多个后端池中,健康检查根据 IP 地址去重防止额外的负载。
转发器的配置管理负责在变更转发规则前解析和校验配置对象。
所有的配置更新都是原子性的。同一个集群里 Maglev 机器的配置可能因为
网络延迟或者健康检查关系暂时不同步。
但是,一致性哈希可以保证在较短时间窗口内,
连接在相同后端池的 Maglev 机器之间漂移。
在同一个集群中可以部署多个 Maglev 分片。
不同 Maglev 切片配置不同且为不同的 VIP 服务。
分片可以提供性能隔离和保证服务质量。
它也能够在不影响常规流量的情况下测试新特性。
本文简化问题,我们假定每个集群中只有一个分片。
3. 转发器设计和实现
转发器是 Maglev 的核心组件,他需要快速且可靠地处理大量的数据包。
本节解释 Maglev 转发器中关键模块的设计和实现细节,以及设计背后的原理。
3.1 总体架构
图4 显示 Maglev 转发器的总体架构。
转发器从网卡接收到数据包,通过合理的 GRE/IP 头重写数据包,再将它们发回网卡。
Linux 内核不参与这个过程。
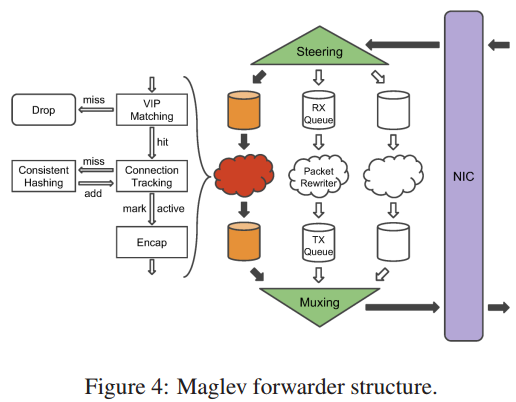
从网卡接收数据包的首先被转发器中的 Steering 模块处理,
即通过 5 元组哈希(s_ip, s_port, d_ip, d_port, ip_proto_num)然后交给不同接收队列。
每个接受队列附加在一个重写包的线程上。
线程首先尝试匹配包到已配置的VIP上,这个步骤过滤了非法的包。
然后重新计算 5 元组哈希,然后在连接追踪表(见 3.3 章)上查找对应的哈希值。
我们没有重复利用 Streeing 模块中的哈希值,避免跨线程的同步。
这个连接表存储了最近连接的后端服务的选择结果。
如果发现匹配了,并且后端仍然健康,则复用改结果。
否则线程查询一致性哈希模块(见 3.4 章节) 同时选择一个新的后端,
同时添加一个新的条目到连接表中。
如果后端不可用,则丢弃数据包。
转发器为每个线程维护一个连接表防止争用。
当后端选择后,线程用合适的 GRE/IP 进行封包,然后发送到附加的传输队列。
然后 Muxing 模块轮询所有的传输队列,再发送给网卡。
Steering 模块使用5元组哈希而不是Round Robin 调度有两个原因。
首先,它降低同一个连接的数据包重排列的可能性,因为不同线程处理的速度的差异导致数据包乱序。
其次,对于连接追踪,转发器只需要为每个连接选择一次后端即可,
节省时钟周期,消除因为后端健康检查更新竞争导致的选择不同后端的可能性。
极端情况下如果接收队列满了,Steering 模块会退化使用Round-Robin 调度,
将数据包发送给其他可用的队列。
这个退化机制在处理大量相同5元组数据包中非常有效。
3.2 快速包处理
Maglev 转发器需要尽快处理数据包,以在满足 Google 流量需求的情况下节省成本。
我们设计它在转发下满足线速 —— 在普遍都是万兆网卡的 Google 集群的今天。
换句话说,对于1500字节的IP包来说,相当于813Kpps。
然后,我们的需求更加严格:我们需要非常高效地处理小包,因为进来的请求通常是小包。
假设IP包的平均大小100字节,转发器必须能够处理 9.06Mpps。
本节的描述了我们达到这个包处理速度的关键技术。
Maglev 是一个运行在通用 Linux 服务器上的用户态程序。
因为 Linux 内核协议栈计算开销非常昂贵,
并且 Maglev 并不需要协议栈的任何特性,
以为这 Maglev 可以在包处理时绕开整个内核。
在合适的网卡硬件的支持下,我们在转发器和网卡之间开发了一套绕开内核的机制,
如图5.
当 Maglev 启动时,预先分配至好网卡和转发器共用的数据包池(Packet pool)。
Steering 和 muxing 模块都维护了一个指针的 ring queue ,指向该数据包池。
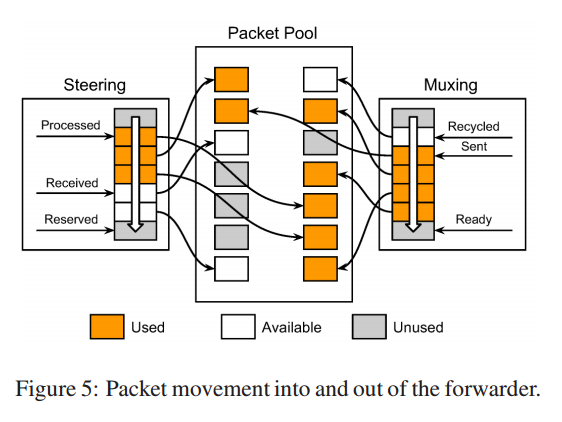
Steering 和 Muxing 模块都为了 3 个指向环形队列的指针。
对于接收端,网卡将新收到的包放在 received 指针位置,然后向前移动该指针。
Steering 模块分发数据包到数据包线程然后向前移动 processed 指针。
它同时从池里保留未使用的数据包,然后放在环形队列中,
并向前移动 reserved 指针。
这三个指针根据箭头一个跟着一个。类似地,在发送端,
网卡将指向 send 指针的数据包发送出去并向前移动指针。
Muxing 模块将重写的数据包发送队列中的ready位置并向前移动指针。
它同时将已被网卡发送的数据包归还给池子并向前移动 recycled 指针。
整个过程都没有包拷贝。
为了减少昂贵跨界操作,我们在可能的时候会批量处理数据包。
另外,数据包线程之间不共享任何数据,避免了他们之间的竞争。
我们将每个线程绑定在固定的 CPU 核上以保证性能。
在所有这些优化措施下, Maglev 能够在处理小包时达到限速,见 5.2 章节。
进而,Maglev 为整个链路增加的延迟非常小。
通常,在我们的标准的机器上, 线程处理的时间为 350ns。
有两种特殊情况会延长处理时间。
因为转发器是批量处理包的,每个批次需要等到数据包达到一定量或者时钟超时。
实现中我们把定时器设为 50 微妙。
因此如果 Maglev 显著地空载,在最坏情况下每个数据包都会增加50微妙的延迟。
一个可能的优化手段就是动态地调整批量的大小[32]。
另一种情况是当 Maglev 过载时,会增加额外的处理时间。
Maglev 能够缓存的最多的数据包的数量依赖于包池的大小。
超过的数据包会被网卡丢掉。
假设包池的大小为3000,转发器能够处理10Mpps,
他需要300微妙来处理所有的缓存的数据包。
因此 Maglev 过载严重的情况, 每个数据包最多会增加300微妙的延迟。
幸运的是,这种情况可以通过合理的容量规划和增加 Maglev 机器解决。
3.3 后端选择
一旦数据包目的符合某个 VIP,我们需要从该VIP的后端池中选择一个合适的后端。
对于面向连接的协议,比如 TCP,需要严格地将同一连接的所有后端发送给同一个后端。
我们通过两部分策略来实现。
首先,我们通过一种新型的一致性哈希算法选择出一个后端,
然后我们将这个抉择保存在本地的连接表中。
Maglev 的连接追踪表使用了固定大小的哈希表映射往后端的数据包的 5 元组哈希值。
如果哈希值在表中不存在, Maglev 会选择一个后端,并保存在表中。
否则 Maglev 简单的复用之前使用的后端。
这个保证了属于同一连接的所有数据包都发给同一个后端,只要后端仍然可以处理数据包。
连接追踪在后端变更中迟早有用:比如,当后端可用或者宕机,增加或者移除,或者权重变化。
然后,每个 Maglev 的连接追踪在我们的分布式环境下是独立的。
首先,它假设所有的拥有相同五元组的数据包都发往同一台 Maglev 机器。
因为上游的路由器通常不提供连接亲缘性,这个假设在一堆 Maglev 机器发生改变时无法保证。
不幸的是,这种改变不可避免同时由于种种原因经常发生。
比如,当升级集群中的 Maglev 时,我们轮流重启机器,
事先将每一台的流量移开一会儿,然后一旦Maglev 启动在恢复。
这个过程可能耗时一个小时,这段时间内,Maglev 的数量持续变化。
我们有时也添加、移除或者替代 Maglev 机器。
所有这些操作会导致标准的 ECMP 实现在很大范围内洗刷流量,导致连接在不同 的Maglev 中切换。
新的 Maglev 并没有正确的连接表项,所有如果此时后端也在变更,会导致连接断开。
第二种理论上的限制是连接追踪表是有限的,
在大压力下或者 SYN Flood 攻击下表容易填满。
因为 Maglev 只有在超时的情况才会移除表项,移动表满了,
我们需要重新为数据包选择后端。
虽然实际中现代的计算机通常有大量的内存,
但在部署中,Maglev 和其他服务是共享机器的,我们需要限制连接表的大小。
如果上述任何一种情况发生,我们没办法依赖单一的连接追踪来处理后端的变更。
所以 Maglev 同时提供一致性哈希来确保在上述情况下的包的可靠性传输。
3.4 一致性哈希
处理连接追踪的限制的一种可行的方法是在所有机器中共享连接状态,
例如利用 [34] 中的分布式哈希表。
然后,这种方法的负面影响是影响转发性能 ——
撤销连接状态甚至在同一台中的 Maglev 机器都会有竞争。
一种更高性能的方法是使用本地的一致性哈希。
一致性哈希的理论[28] 或者 Rendezvous 哈希[38] 在 1990年代被提出来。
它通过生成一张带有每个后端的大的查询表来实现。
这种方法提供两种符合 Maglev 复原后端选择的特性:
- 负载均衡: 每个后端收到几乎相等的链接
- 最小破坏: 当一堆后端出现变更,一条连接几乎被发往同一个后端
[28] 和 [38] 都是通过负载均衡优先最小打断,他们设计目标为小数量服务优化网页缓存。然后, Maglev 有两个原因 take the opposite approach。
首先, Maglev 尽可能地均衡负载到后端的服务非常重要。
否则,后端服务必须提供额外的冗余服务来承担峰值流量。
Maglev 中,对于某些VIP,可能有数以百计的后端服务与之对应,
我们的经验发现 [28] 和 [38] 对于每个 VIP 都需要一个过于庞大的查询表,
以满足 Maglev 需要的负载均衡能力。
其次,尽管最小化查询表disruptions 非常重要,
但那时一小数量的 disruption 对于 Maglev 是可以容忍的。
稳定的状态,对查询表的更改不会导致连接重置,因为对连接亲缘的 Maglev 不会同时地改变。
当连接亲缘的 Maglev 改变时,对于一定量的查询表破坏会有成比例的重置。
经过上述的考虑,我们设计了一种新型的一致性哈希算法,我们称之为 Maglev 哈希。
Maglev 哈希的基本思想就是给每个后端一个
所有查询表位置的优先列表。
然后所有的后端轮流填充他们最感兴趣的表中的空白位置,直到整张表都完全填满。
因此, Maglev 哈希几乎为每个后端共享了一张查询表。
通过更改相应的后端次序的频率可以得到相异的后端权重;
这个细节本文并未涉及。
设 M 为查询表的大小。
后端 i 感兴趣的列表存储在 permutation[i] 中,permutation[i] 是一个数组 (0, M-1) 的随机排列。
一个快速生成 permutation[i] 的方法,
每个后端都一个唯一的名字。
我们首先用两个不同的哈希方法对这个名字进行哈希,
产生两个数字 offset 和 skip。
然后使用这些数字产生 permutation[i]:1
2
3offset = h1(name[i]) mod M
skip = h2(name[i]) mod (M-1) + 1
permutation[i][j] = (offset + j * skip) mod M
M 必须是质数,这样所有 skip 都与之互质。
设 N 为一个 VIP 后端池的大小。
填充它的查询表的算法如伪代码1。
我们使用next[i] 来追踪后端 i 的 permulation[i] 中下一个位置,最后的查询表存储在 entry 中。
算法外层的 while,我们遍历所有的后端。
对于每个后端 i 我们从 permutation[i] 中找到一个候选的索引 c,该位置的查询表还是空的,
然后把该位置的填充为后端 i。
如此循环直到查询表的所有位置均被填充完毕。
Pseudocode 1 Populate Maglev hashing loockup table.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18function Populate
for each i < N do next[i] = 0 end for
for each j < M do entry[j] = -1 end for
n = 0
while true do
for each i < N do
c = permutation[i][next[i]]
while entry[c] >= 0 do
next[i] = next[i] + 1
c = permutation[i][next[i]]
end while
entry[c] = i
next[i] = next[i] + 1
n = n + 1
if n == M then return end if
end for
end while
end function
这个算法确保可以终止。
最坏情况复杂度为 O(M^2),
当后端数量与查询表大小相当且所有的后端被哈希成相同的 permutation。
为了避免这种情况,我们总是选择 M 使 M >> N。
平均复杂度为 O(MlogM),
因为步骤 n 我们期望算法尝试 M/(M-n) 步去查找一个空白的候选位置,
这样总的查找步数就是 sum(M/n, n = 1...M)。
每个后端在查询表中拥有 floor(M/N) 或者 ceil(M/N) 个项。
因为查询表中不同后端最多的差异项为1。
实际中,我们选择 M 大于 100*N,来确保哈希空间内最多有1%的差异。
另外产生随机排列的算法,比如 Fisher-Yates Shuffle[20],
用更多的状态产生更好排列,同样也很有效。
表 1 一个一致性查询表的示例
| 编号 | B0 | B1 | B2 |
|---|---|---|---|
| 0 | 3 | 0 | 3 |
| 1 | 0 | 2 | 4 |
| 2 | 4 | 4 | 5 |
| 3 | 1 | 6 | 6 |
| 4 | 5 | 1 | 0 |
| 5 | 2 | 3 | 1 |
| 6 | 6 | 5 | 2 |
后端的列表
| 编号 | Before | Alfter |
|---|---|---|
| 0 | B1 | B0 |
| 1 | B0 | B0 |
| 2 | B1 | B0 |
| 3 | B0 | B0 |
| 4 | B2 | B2 |
| 5 | B2 | B2 |
| 6 | B0 | B2 |
查询表在 B1 移除前后
我们使用例子如表1,来展示 Maglev 哈希的工作流程。
假设有三个后端: B0, B1, B2, 查询表的大小为7,
同时(offset, skip) 分别为 (3,4), (0,2), (3,1)。
生成排列表为表1的上,查询表在 B1 移除前后的变化如表1的下。
如例子所示,查询表在包含/不包含B1的情况下都较均衡。
在B1移除之后,除了更新所有包含B1的条目,只要再更新条目6即可。
实际应用中,在大的查询标下, Maglev 哈希能fairly的应对后端的变更恢复,见 5.3 章节。
4. 操作经验
Maglev 作为一个高度复杂的分布式系统,已经在 Google 服役了6年。
在全球范围的运作中,我们学到了很多经验。
本章描述了这些年在适应我们需求的变更中 Maglev 的进化过程,
以及一些用来监控调试系统的工具。
4.1 Maglev 的进化
今天的 Maglev 和原始的系统已经有诸多的不同。
许多的变化,例如 IPv6 的支持,因为是可扩展的软件架构使变化非常平滑。
本节谈论了两个自诞生以来的实现和部署的最大变化。
4.1.1 故障恢复
最早的 Maglev 机器成对地部署以应对故障恢复能力,
就如同被他们替代的硬件负载均衡器。
通常情况下只有活跃的机器才提供服务。
当活跃的机器变成不健康时,它的备机就会开始服务。
得益于 Maglev 哈希,这一过程通常不会造成连接中断,
但是这样部署有一些弊端。
首先浪费资源,它总是有一般的机器处于空闲状态。
同时单台机器的能力也阻碍我们扩展任何的 VIP。
最后,协调活跃和备份的机器也很复杂。
这种部署中,机器的宣告者会监控彼此的健康度和服务优先级,
在失去对方的时候提升自己BGP的优先级及其他多种机制。
在迁移到 ECMP 模型之后我们得到一大容量、效率以及操作便利上的益处。
同时 Maglev 哈希继续保护我们应对偶尔的 ECMP 抖动,
我们可以最大化路由的 ECMP 大小成倍地提升一个VIP的容量,
同时所有的机器都能被充分利用。
4.1.2 包处理过程
原来 Maglev 使用的 Linux 内核协议栈处理包。
必须通过内核socket 与网卡交互,
这会因为硬件中断和软件中断、上下文切换、系统调用[26]等给处理过程带来很大的负担。
每个包必须从内核态拷贝到用户态,处理完再拷贝回去,也增加了很多负担。
Maglev 并不需要 TCP/IP 栈,只需要为每个包寻找一个合适的后端以及用 GRE 封包即可。
因此我们利用了 bypass kernel 的机制之后,在不削减功能的情况下
极大地改善了性能 —— 每台 Maglev 机器的吞吐量提高了 5 倍。
4.2 VIP 匹配
Google 生产环境的网络,每个集群都给一个外网 IP 的前缀用来全球路由。
例如, 如图6, 对于集群C1 拥有 74.125.137.0/24 的前缀。
一个相同的服务在另外一个集群配置了另外的VIP,
用户通过 DNS 来访问他们。
例如,Service1 在 C1中配置为 74.125.137.1, C2中为 173.194.71.1。
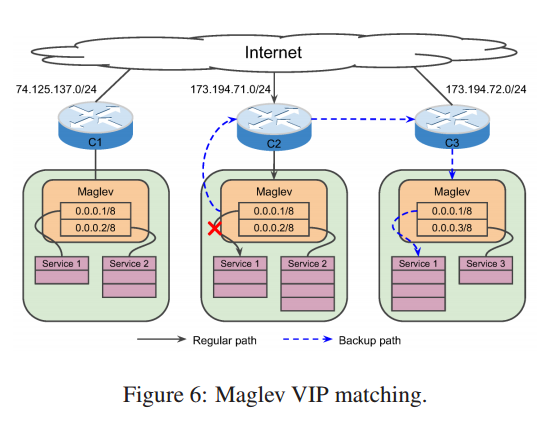
Google 拥有很多集群的级别,服务的不同的 VIP。
同一个级别的集群拥有相同的前缀长度,但是不同级别的集群长度可能不一样。
有时紧急情况下,我们需要利用 Maglev 封包将流量重定向到其他的集群中。
因此,我们需要目标 Maglev 能够正确识别从任意其他集群来的流量。
一种可行的方案是在所有可能收到重定向流量的集群中定义所有 VIP,
但是会有同步和可扩展性的问题。
取而代之,我们实现了一个特殊的编号规则和一个特别的 VIP 匹配机制来解决这个问题。
对于每个集群级别,我们赋予每个 VIP 相同的后缀(所有当前相同级别的集群都一致)。
然后我们使用一个前缀/后缀匹配机制来匹配 VIP。
首先,进来的包经过最长前缀匹配,以决定目标是哪个集群级别。
然后在特定集群级别中,经过最长后缀匹配决定那个后端池。
为了减少在严格时间尺度下需要全局同步的配置量,
拥有相同前缀的同级别新集群创建是,我们在 Maglev 预先配置了相应集群级别足够的前缀组.
这样 Maglev 可以正确的处理原始目的是陌生集群的重定向流量。
结果,每个 VIP 都会配置为
例如图6,假设集群 C2 和 C3 同属于一个级别,
如果一个被C2接收到的数据包目的是 173.194.71.1,
但是C2 的 Maglev 并无法确认可服务的后端时,
它会封包之后,透过隧道传给 C3 相同服务的 VIP(173.194.72.1)。
然后 C3 的 Maglev 解包之后用前缀/后缀匹配包内的 VIP 得到是传给 Service1 的,
然后数据包被 C3 的后端正确处理。
这个 VIP 匹配机制是为 Google 生产环境部署特定的,
但是它为软件负载均衡器提供了一种用于快速原型匹配和迭代的良好范例。
4.3 分片处理
截至目前,本文还未涉及到 IP 分片。
分片处理需要特别的技巧,因为 Maglev 为大部分 VIP 提供的是五元组哈希,
但是分片信息并不包含五元组所需的全部信息。
例如,一个大的报文被分成两个分片,
第一个分片包含 L3 和 L4 的头,但是第二个分片只包含 L3 的头。
因此当 Maglev 接收到非首个的分片时,它并没有办法单纯依据包头来正确决定如何转发。
为了正确处理分片,Maglev 必须符合两个要求。
首先,所有相同数据报文的分片必须被路由到同一台 Maglev 上。
其次,Maglev 必须能为非分片、首个分片和非首个分片选择同一个后端。
通常,我们并不能依赖 Maglev 前面的硬件设备来满足第一个条件。
例如,有些路由器为首个分片做五元组哈希但是为非首分片做三元组哈希。
我们因此需要在 Maglev 中实现一个通用的满足任何分片哈希行为的解决方案。
每个 Maglev 配置了一个特殊的后端池,包含所有的 Maglev 机器。
一旦接收到首个分片, Maglev 用 L3 的头计算三元组哈希,
然后根据哈希值选择特定的 Maglev 作为后端进行转发。
因为所有属于相同报文的分片总是有相同的三元组,
能够保证他们都被重定向给相同的 Maglev。
我们使用 GRE recusion control 字段,确保分片只能被重定向一次。
为了满足第二个条件, Maglev 为未分片数据包和第二跳的首分片(通常在不同的 Maglev 实例上) 使用相同的后端决策算法。
它维护了一个固定大小的分片表,记录了首分片的转发决策。
当同一台 Maglev 收到一个第二跳非首分片,
会从分片表中查找,若匹配则立即转发;
否则,会缓存到分片表中,直到首分片收到或者老化。
这种方法有两种限制:
首先导致分片被额外传输一次,有可能会导致数据包乱序。
另外需要额外的内存来缓存非首分片。
因为网络中任何地方都可能导致包乱序,
我们需要依赖后端来处理乱序包。
实际中一个极少数 VIP 允许分片报文,
我们很容易就能提供一个足够大的分片表来处理这些。
4.4 监控和调试
和监控其他生产系统一样,我们监控每个 Maglev 机器的健康程度和行为。
例如,我们使用了黑盒监控和白盒监控。
我们的黑盒监控包含遍布全世界的 Agent,周期性地检查 VIP 的可访问性和
延迟。
对于白盒监控,每个 Maglev 都会利用 HTTP Server 导出一些指标,
然后监控系统周期性的拉取并计算服务状态信息。
当出现异常行为时监控系统会发报警。
由于 Maglev 的分布式特性,从路由器到 Maglev 到服务存在着多条路径。
但是,调试时,我们能够用特定的数据包来识别具体的路径。
因此我们开发了 packet-tracer,类似于 X-Trace[21]。
Packet-tracer 构造和发送特殊的 Maglev 能够识别的三层和四层的数据包。
数据包内容包含需要 Maglev 发送调试信息的接收者的 IP。
数据包的目的通常是一个特殊的 VIP,可能被正确地路由到我们的前端集群。
当 Maglev 接收到 Packet-tracer 的数据包时,它会照常转发,但是同时会把
包含当前机器名、选择的后端等调试信息发送给数据包指定的接收者。
Packet-tracer 数据包会被 Maglev 限速,因此他们处理比较耗时。
这个工具在调试生产环境的问题非常管用,
特别是发生分片时有多台 Maglev 在链路中。
5. 评估
本章我们评估了 Maglev 的效率和性能。
我们展示了某个 Google 生产集群以及一些微基准测试的评估结果。
5.1 负载均衡
作为一个网络负载均衡器, Maglev 的主要职责就是把流量均衡到多台后端服务上。
为了展示 maglev 的负载均衡的性能,
我们收集了一个位于欧洲集群的 458 个 endpoint 的 cps (Connections Per Second)。
这个数据是多个HTTP服务的聚合,包含搜索服务。
数据收集粒度为5分钟,负载用每天的平均 cps 标准化。图7 显示了某天所有 endpoint 的负载的平均值和标准差。
流量负载的显示了一天的趋势。相对于平均负载,标准差一直都很小,变异系数大多数时间在 6% ~ 7%之间。
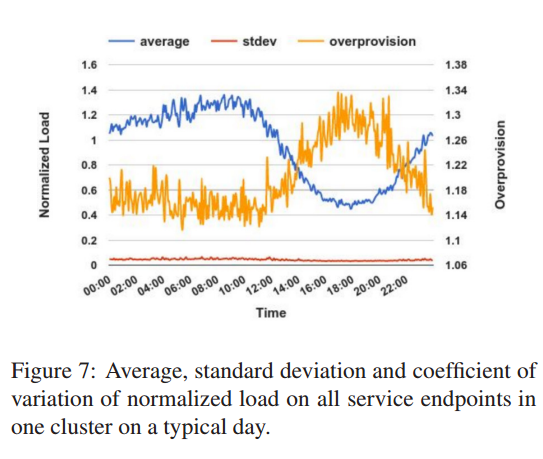
图7同时显示了每个时间点最高负载与平均负载的冗余系数。
冗余系数非常重要,我们总是要确保最繁忙的节点有足够的能力处理所有流量。
冗余系数在 60% 的时间段小于 1.2。
在非峰荷时段冗余系数比较高,这是合理的,
因为低流量时比较难以平衡负载。
另外,非峰荷时段高冗余系数也不需要额外的 Maglev 机器。
5.2 单机吞吐量
因为每台 Maglev 机器通过 ECMP 收到差不多的流量,
总的吞吐量的估算可以通过机器数量乘以单机吞吐量简单计算得到。
单机承担的能力越高,所需要的机器就越少。
因此单机吞吐量是整个系统效率的关键。
Maglev 单机的吞吐量受很多因素的影响,包括处理线程的个数、
网卡速度、流量类型等。
本节我们在一系列条件下透过一小个试验台来评估单台 Maglev 处理数据包的能力。
除非特别说明,所有的实验机器均为以下配置:
两个当前服务端的8核CPU,1个万兆网卡和 128GB 内存。
我们只给 Maglev 使用1个CPU,其他的包含操作系统,在另外一个CPU上运行。
实验台包含位于同一个以太网域内的两个发送端、两个接收端和1台Maglev机器。
发送端缓慢地增加发送速率,
同时记录Maglev 处理的 pps,记录最大值和何时开始丢包。
我们使用两个发送端是为了确保 Maglev 能够过载。
5.2.1 Kernel Bypass
试验中,我们让 Maglev 跑在 Linux 主线版本内核(即 vanilla kernel)协议栈和跑在 Kernel bypass 模式下,
对比 Maglev 的吞吐量。
发送端从不同的源端口发送最小的UDP包,以确保 Maglev 的 Steering
模块中不会被转给一个处理线程处理。
由于测试环境的限制,最小的 UDP包大小为 52 字节,略大于理论上的以太网内最小包大小。
同时也更改线程的数量,每个线程绑到固定的核上(与生产环境一致)以保证性能。
我们用了1个核来处理 Steering 和 Muxing,因此最多有7个工作线程。
包含和不包含 Kernel bypass 的测试结果见图8.
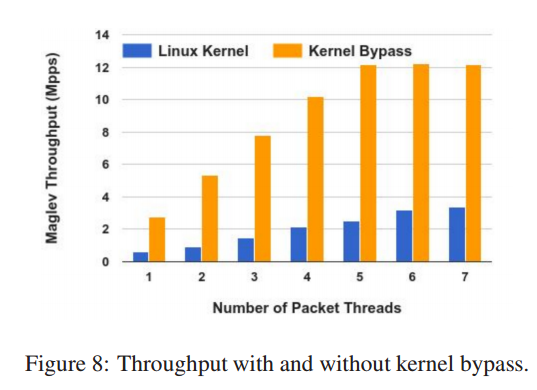
图中显示 Maglev 在 Kernel Bypass 下拥有明显的性能优势。在不超过4个线程时, Maglev 是瓶颈,吞吐量随线程数线性增长。
当超过4个线程时,网卡成为了瓶颈。
另一方面,在用协议栈时, Maglev 总是瓶颈,能达到的最大吞吐量只有 Kernel Bypass 的 30%不到。
5.2.2 流量类型
依据处理线程中的代码执行路径, Maglev 处理不同类型流量的速度有所差别。
比如,一个线程需要为 TCP 的SYN包 选择一个后端并记录到连接追踪表中,
对于非 SYN 包只需要查表即可。
本节测试中,我们测试 Maglev 处理不同 TCP 类型包能力。
有三种类型需要考虑: SYN、非SYN以及固定五元组。
对于SYN和非SYN 实验,只发送 SYN 和 非 SYN 包。
SYN 包实验显示 Maglev 在应对 SYN Flood 时的表现,
非 SYN 包显示 Maglev 在处理常规 TCP 流量的表现。
对于固定五元组的实验,所有数据包包含相同三层和四层的头,
这个特殊的用例是因为 Steering 模块通常尝试将相同的五元组指派给同一个线程处理,
只有当目标线程的处理队列满了之后才会指派给其他线程。
发送SYN和非SYN 发送端变换不同的源端口来产生不同的五元组,
但是对于固定五元组,则使用固定的端口。
这些实验总是发送最小的 TCP 包 —— 即 64 字节。
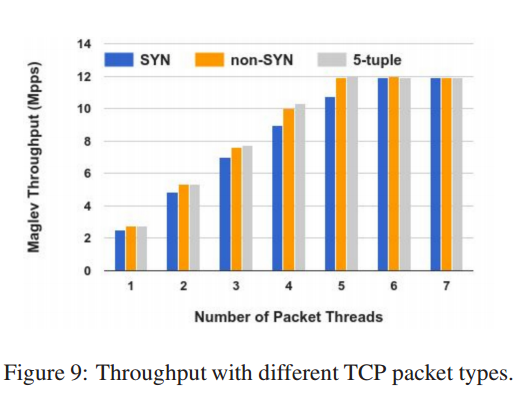
如图9, 这些试验中,在非 SYN 和固定五元组中, 5个处理线程就达到网卡的极限。
但是对于 SYN 包, Maglev 需要 6 个线程才能跑满网卡。
因为 Maglev 需要为每个 SYN 选择一个后端。
Maglev 在固定五元组也拥有很高的性能,表明 Steering 模块
可以高效地处理非离散的数据包。
因为所有的包拥有相同的五元组,那么他们连接追踪表的信息总是在 CPU Cache中,
保证了最高的吞吐量。
对于非 SYN 包,表查找过程由不时地Cache miss,因此在5线程以内,性能略低于固定五元组。
5.2.3 网卡速度
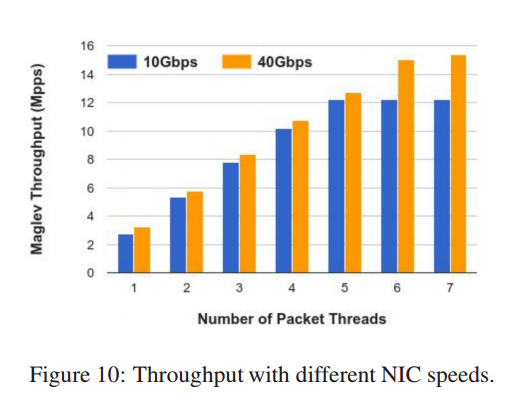
在前面的试验中, 网卡在5个线程时就跑满了。
为了测出 Maglev 的所有能力,这个实验使用了更快的网卡来评估吞吐量。
为此我们使用了 40Gbps 网卡代替10Gbps,然后与 5.2.1 节一样的测试环境。
结果见图10。当不超过5线程时, 40Gbps网卡只能略高于10Gbps网卡,因为40 Gbps的芯片比 10Gbps好。
但是对于40Gbps,当先线程到7个时,吞吐量的增长率没有下降。
因为网卡不再是瓶颈,这张图显示了Maglev在当前硬件条件下的性能极限——略高于 15Mbps。
实际上,瓶颈是 Maglev 的Steering 模块,未来切换到40Gbps网卡时我们会继续优化。
5.3 一致性哈希
这个实验中我们对比评估 Karger[28]、 Rendezvous[38] 哈希和 Maglev 哈希的性能。
我们关注两个指标: 负载均衡的效率和后端变更的恢复能力。
为了评估这些方法的效率,我们用每个方法构建查询表,然后统表计设置后端实例的条目数。
我们设定后端数目为1000个,查询表的大小为65537和655373。
对于 Karger 我们设定视图数目为1000。
图11展示了每种方法的表大小、每个后端的最小和最大条目比例。
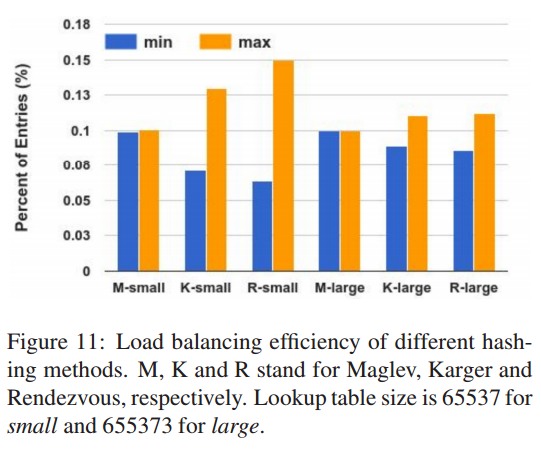
正如期望的,无论表达小如何,Maglev 哈希提供了几乎完美的负载均衡特性。
当表大小为65537时, Karger 和 Rendezvous 为了应对不平衡的流量,需要后端的冗余分别达到29.7%和49.5%。
当表大小为655373 是,数目降为 10.3% 和 12.3%。
因为每个VIP都需要查询表,因此需要控制表大小。
因此 Karger 和 Rendezvous 并不能满足 Maglev 负载均衡需求。
另一个重要的指标是一致性哈希应对后端变化的应对能力。
Karger 和 Rendezvous 保证当某些后端失效, 剩余的后端均不会有影响。
因此我们只需要评估 Maglev 哈希这个指标即可。
图12 展示了不同比例后端失效的情况,表中需要变化的条目个数。
我们同样设定后端数目为1000. 对于每个失败数 k, 我们随机从池中移除 k 个后端,
然后重新生成表并计算表变更的数目。
对于每个 k,我们重复了 200 次实验,然后计算平均值。
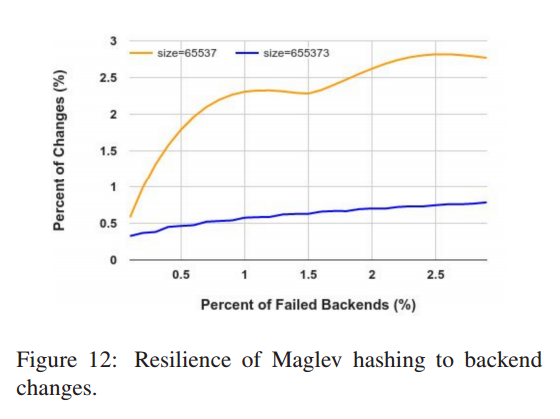
图12 展示随着同时失败数目的增加,需要变更条目数目的比例也逐步增加。
Maglev 哈希在表大小更大的情况应对恢复的能给力越好。
实际应用中我们使用了 65537 作为表的默认大小因为我们发现同时失败的后端数目非常少见。
同时我们还有连接追踪做保证。
另外,微基准测试表明,查询表生成时间在表大小从65537到655373时,从1.8ms增长到22.9ms,这也限制了我们无节制增加表大小。
6. 相关工作
不像传统的硬件负载均衡器[1,2,3,5,9,12,13], Maglev 是一个运行在通用服务器上的分布式软件系统。
硬件负载均衡器通常需要以主备的形式成对部署。
Maglev 以多主的形式更加高效和更富有弹性。
而且,升级硬件负载均衡器的能力需要额外的购买机器
以及物理部署,使得按需调整能力更加困难。
但是,Maglev 的能力可以简单地通过增加和减少 Maglev 节点
进行调节,而无须中断服务。
有些硬件服务商也提供了虚拟化环境的负载均衡软件,但Maglev 相比较拥有更高的吞吐量。
Ananta[34] 是一个分布式的软件负载均衡器,与 Maglev 类似,
它也是通过 ECMP 来扩容,以及使用一个流表来获得连接亲缘性。
然后,它并没有提供具体的机制来柔性处理负载均衡池的变更,
同时它也没有特别优化单机性能。
Maglev 没有提供类似 Ananta HostAgent 这种 NAT 服务,
但是有一个外部系统(本文并未涉及)来达到类似功能。
Ananta 允许最多内部VIP 流量绕过负载均衡器,
Maglev 没有提供此功能是因为本身已经拥有足够的能力处理内部流量。
Embrane[4] 是一个为虚拟环境开发的类似系统。
但是它吞吐量优化受限于虚拟环境的限制。
Duet[22] 是一个硬件和软件的混合负载均衡器,旨在解决纯软的低吞吐量问题。
Maglev 有可能达到较高的性能,因此混合模式变得没有必要。
还有许许多多通用负载均衡软件包,最流行的如 NGINX[14]、 HAProxy[7] 以及 LVS[11]。
他们通常运行在单机上,但是也可以通过 ECMP 组来多机部署,达到横向扩展的能力。
他们都提供一致性哈希的机制。
与 Maglev 相比,他们就如同 [28] 和 [38] 一样,最小打断优先于公平负载均衡。
因为他们的设计目标是可移植性,所以并没有花大力气优化性能。
一致性哈希[28] 和 Rendezvous 哈希 [28] 提出的原始目的是为了协调分布式缓存。
两种方法都能保证回弹能力,即当某些后端移除,只有这些后端相关的条目会被更新。
但是他们并没有很好的提供对LB来说非常重要的负载均衡性。
相对的, Maglev 一致性哈希方法能够达到完美的均衡以及很少的回弹代价,
实际中也很好的与连接追踪结合。
另一种实现一致性哈希的方法是分布式哈希,类似于 Chord[37],
但是这会给系统带来额外的延迟和复杂度。
Maglev 中一些性能优化手段从上个世纪90年代已经出现。
Smith 等[36] 建议通过减少中断和内存拷贝来提供吞吐量。
Mogul 等[33] 开发了基于轮询机制来避免收到中断产生的活锁。
Edwards 等[19] 探寻了在用户态处理网络的方法,但是并没有完全绕过内核。
Marinos 等[31] 显示绕过内核的专门的用户态协议栈能够显著地提高应用的吞吐量。
Hanford 等[25] 提出跨多个CPU 核分发包处理,提高 CPU 缓存命中率。
CuckooSwitch [41] 是一个高性能2层软件交换机。
它的一个核心技术就是通过批量处理和预取的方式降低内存访问延迟。
RouteBricks[18] 解释了如何通过并行处理包来高效地利用多核CPU。
最近业界有一些内核旁路的技术,包括 DPDK[8]、 OpenOnload[15]、netmap[35] 以及
PF_RING[17] 等。
[10] 是对这些流量的内核旁路方案技术的良好总结。
这些技术可以非常有效地提高包处理速度,但是他们都有局限性。
例如 DPDK 和 OpenOnload 都与具体网卡型号/提供商绑定,
netmap 和 PF_RING 都需要修改 Linux 内核。
在 Maglev 中,我们实现了一个灵活的 I/O 层,让我们无须修改内核并能够方便地切换不同的网卡。
像其他技术, 一旦 Maglev 启动之后,它会接管网卡,然后使用 TAP 设备将数据包注回内核。
最近,GPU 在高速包处理中越来越流行[24, 39]。
但是, Kalia 等[27] 最近发现基于 CPU 的解决方案也能达到类似的性能,
而且在正确实现的情况下资源利用更高效。
7. 结论
本文展示了 Maglev, 一个高效、可靠、可扩展和灵活的软件网络负载均衡器。
我们通过 ECMP 来横向扩展 Maglev,同时每台机器都能在万兆网卡下达到线速,
在高速增长的业务需求下提供划算的性能。
我们结合连接追踪和 Maglev 哈希,将相同的连接映射到同一个后端。
多年来大规模地应用让我们高效地把控网站,
以及在需求增长或者未来新需求下快速反应。
致谢
略
引用
- [1] A10. http://www.a10networks.com.
- [2] Array networks. http://www.arraynetworks.com.
- [3] Barracuda. http://www.barracuda.com.
- [4] Embrane. http://www.embrane.com.
- [5] F5. http://www.f5.com.
- [6] Google cloud platform. http://cloud.google.com.
- [7] Haproxy. http://www.haproxy.org.
- [8] Intel dpdk. http://www.dpdk.org.
- [9] Kemp. http://www.kemptechnologies.com.
- [10] Kernel bypass. http://blog.cloudflare.com/kernel-bypass.
- [11] Linux virtual server. http://www.linuxvirtualserver.org.
- [12] Load balancer .org. http://www.loadbalancer.org.
- [13] Netscaler. http://www.citrix.com.
- [14] Nginx. http://www.nginx.org.
- [15] Openonload. http://www.openonload.org.
- [16] F. Chen, R. K. Sitaraman, and M. Torres. End-user mapping:
Next generation request routing for content delivery. In Proceedings
of SIGCOMM, 2015. - [17] L. Deri. Improving passive packet capture: Beyond device
polling. In Proceedings of SANE, 2004. - [18] M. Dobrescu, N. Egi, K. Argyraki, B.-G. Chun, K. Fall, G. Iannaccone,
A. Knies, M. Manesh, and S. Ratnasamy. Routebricks:
Exploiting parallelism to scale software routers. In Proceedings
of SOSP, 2009. - [19] A. Edwards and S. Muir. Experiences implementing a high performance
tcp in user-space. In Proceedings of SIGCOMM, 1995. - [20] R. A. Fisher and F. Yates. Statistical tables for biological, agricultural
and medical research. Edinburgh: Oliver and Boyd,1963. - [21] R. Fonseca, G. Porter, R. H. Katz, S. Shenker, and I. Stoica. Xtrace:
A pervasive network tracing framework. In Proceedings of
NSDI, 2007. - [22] R. Gandhi, H. H. Liu, Y. C. Hu, G. Lu, J. Padhye, L. Yuan, and
M. Zhang. Duet: Cloud scale load balancing with hardware and
software. In Proceedings of SIGCOMM, 2014. - [23] P. Gill, N. Jain, and N. Nagappan. Understanding network failures
in data centers: Measurement, analysis, and implications. In
Proceedings of SIGCOMM, 2011. - [24] S. Han, K. Jang, K. Park, and S. Moon. Packetshader: A gpuaccelerated
software router. In Proceedings of SIGCOMM, 2010. - [25] N. Hanford, V. Ahuja, M. Balman, M. K. Farrens, D. Ghosal,
E. Pouyoul, and B. Tierney. Characterizing the impact of endsystem
affinities on the end-to-end performance of high-speed
flows. In Proceedings of NDM, 2013. - [26] V. Jacobson and B. Felderman. Speeding up networking.
http://www.lemis.com/grog/Documentation/vj/lca06vj.pdf. - [27] A. Kalia, D. Zhou, M. Kaminsky, and D. G. Andersen. Raising
the bar for using gpus in software packet processing. In Proceedings
of NSDI, 2015. - [28] D. Karger, E. Lehman, T. Leighton, R. Panigrahy, M. Levine,
and D. Lewin. Consistent hashing and random trees: Distributed
caching protocols for relieving hot spots on the world wide web.
In Proceedings of ACM Symposium on Theory of Computing,1997. - [29] C. Labovitz. Google sets new internet record.
http://www.deepfield.com/2013/07/google-sets-new-internetrecord/. - [30] C. Labovitz, S. Iekel-Johnson, D. McPherson, J. Oberheide, and
F. Jahanian. Internet inter-domain traffic. In Proceedings of SIGCOMM,2010. - [31] I. Marinos, R. N. Watson, and M. Handley. Network stack specialization
for performance. In Proceedings of SIGCOMM, 2014. - [32] J. C. McCullough, J. Dunagan, A. Wolman, and A. C. Snoeren.
Stout: An adaptive interface to scalable cloud storage. In Proceedings
of USENIX ATC, 2010. - [33] J. C. Mogul and K. K. Ramakrishnan. Eliminating receive livelock
in an interrupt-driven kernel. In Proceedings of USENIX
ATC, 1996. - [34] P. Patel, D. Bansal, L. Yuan, A. Murthy, A. Greenberg, D. A.
Maltz, R. Kern, H. Kumar, M. Zikos, H. Wu, C. Kim, and
N. Karri. Ananta: Cloud scale load balancing. In Proceedings
of SIGCOMM, 2013. - [35] L. Rizzo. netmap: A novel framework for fast packet i/o. In
Proceedings of USENIX Security, 2012. - [36] J. Smith and C. Traw. Giving applications access to gb/s networking.
Network, IEEE, 7(4):44–52, 1993. - [37] I. Stoica, R. Morris, D. Karger, M. F. Kaashoek, and H. Balakrishnan.
Chord: A scalable peer-to-peer lookup service for internet
applications. In Proceedings of SIGCOMM, 2001. - [38] D. G. Thaler and C. V. Ravishankar. Using name-based mappings
to increase hit rates. IEEE/ACM Transactions on Networking,
6(1):1–14, 1998. - [39] M. Varvello, R. Laufer, F. Zhang, and T. Lakshman. Multi-layer
packet classification with graphics processing units. In Proceedings
of CoNEXT, 2014. - [40] K. V. Vishwanath and N. Nagappan. Characterizing cloud computing
hardware reliability. In Proceedings of SoCC, 2010. - [41] D. Zhou, B. Fan, H. Lim, M. Kaminsky, and D. G. Andersen.
Scalable, high performance ethernet forwarding with cuckooswitch.
In Proceedings of CoNEXT, 2013.